QA Environments on Demand with Kubernetes

Update: Acyl is now open source!
Several years ago the Engineering team at Dollar Shave Club had a challenge: we only had one pre-production staging environment where we could test features (we called it “QA”), and it was getting painful for everybody to share this single environment.
Our initial solution was to clone the environment into multiple copies. Eventually we had ten (called “qa-1” to “qa-10”), but as the team continued to grow it became frustrating figuring out who “owned” a QA at any given time and, if so, when they were done with it. We tracked this on a shared Google spreadsheet but it was far from ideal.
These static QA environments were created using a set of Ansible playbooks, and code was deployed using a set of Jenkins jobs which used Capistrano. The process of creating the environments was manual, tedious and error-prone. The stack consists of many frontend and backend applications that work together and which must be brought up in a particular configuration. Engineers had to deploy changes to each application on a QA environment separately, and if they forgot to deploy one of them subtle bugs would result.
The Infrastructure Team (now Platform Services) decided that we needed a better way for engineers to test pre-production code, and this required building something novel and scalable. Simultaneously we were working on switching all of our systems to use Docker containers instead of direct code checkouts, so it made sense to leverage container technology for this as well.
The initial idea we came up with was a system that would spin up copies of our “devbox” (local Vagrant development VM) in AWS on demand. We decided to build this centered around GitHub pull requests to fit in with the workflow everybody was already used to. Within a week or two we had a functional proof-of-concept based on AWS Lambda, DynamoDB and an internal service called Thalamus which was responsible for creating EC2 instances.
The general idea was as follows:
- An engineer opens up a pull request from their feature branch (e.g., “feature-foo”) of one of the application repositories.
- The GitHub PR sends a webhook to a Lambda function.
- The Lambda function triggers Thalamus to create a new EC2 instance running CoreOS, with a userdata script that pulls and runs application containers in a particular order.
- As various applications on the instance start up, they ping a Lambda function to report the environment status.
- When the startup finishes, the instance triggers a final Lambda function that reports the environment as successful, creates Route53 DNS records and marks the GitHub commit status as green.
- When the engineer closes/merges the PR, it sends a webhook to a “destroy” Lambda function that terminates the EC2 instance and does clean up.
- The result is a dynamic environment running “feature-foo” of the application in question and production versions of all other applications.

This worked pretty well for a POC, but we quickly realized that we needed a way for engineers to control revisions of supporting applications since sometimes a feature spanned multiple repositories and they all needed to be tested on the same environment. After discussion with the application teams we came up with a scheme we called branch matching, the design of which fit with the convention-over-configuration philosophy that we liked elsewhere in our tech stack.
Branch matching works like this:
- For each supporting application, if a branch exists with the same name as the primary application (e.g., “feature-foo”), use it for the new environment.
- If that branch doesn’t exist, fall back to the base branch of the PR that triggered the environment creation (e.g., “master”).
- If that branch doesn’t exist either, abort and signal an error to the developer.

Branch matching has worked extraordinarily well, and we still use it today. The system is flexible enough that different teams can collaborate on features and all they need to do is agree on a shared branch name and all their testing environments will be consistent. Advanced workflows like a shared trunk branch are also easily supported.
Introducing Acyl
Over time it became obvious that we needed to overhaul the architecture of the system. Reliability was not what we had hoped for, environment creation was slow and as the application stack became more complex we were outgrowing what a single EC2 instance could comfortably run.
To address some of these issues we started by eliminating Lambda and rewrote the system in Go (calling it Acyl) as an API-compatible drop in replacement. We improved the UX by allowing developers to modify behavior with an acyl.yml file in their repository, and added Slack notifications. After growing frustrated with a third party Docker image building service we implemented our own container build service called Furan, now used by Acyl to build Docker images with a high degree of parallelism.
Enter Amino
At this point we started investing heavily in Kubernetes. As we started to test production workloads on our cluster, it made sense to think about how Acyl could leverage this orchestration system for environment creation.
The result was a new microservice named Amino — also written in Go — utilizing GRPC and serving as an environment creation backend for Acyl. The decision to implement it as a separate microservice was driven by the desire to minimize changes to the Acyl codebase, while allowing us to incrementally move workload over to the new backend as it (and the Kubernetes cluster) proved itself over time. Within a few weeks we were running all environments on K8s and haven’t looked back.
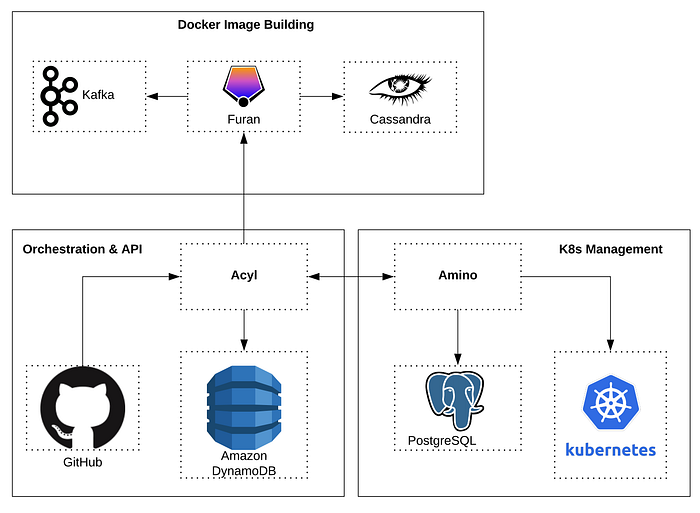
Since then, challenges related to Amino running as a separate service have led us to integrate the codebase into Acyl. Luckily Go’s flexible package system made this relatively painless, though we had to deal with minor complications related to each having separate data stores (DynamoDB and PostgreSQL). This has since been fixed (we’re now consolidated on Postgres).
Currently we’re working on Amino v2 — with backend improvements — and a redesign of the Acyl UX called Nitro, modeled after the YAML UX of SaaS products like CircleCI and TravisCI.

Looking Ahead
At DSC, “DQAs” (dynamic QAs) powered by Acyl are the runway through which we deliver software. They are an indispensable part of each engineer’s daily work. We run dozens at any given time in addition to production and our legacy staging environment. Each DQA consists of >50 pods and consumes many GB of memory (something we’re working on reducing). Average environment creation time — including container builds — is 8 minutes from PR open to environment ready (also something we’re working on reducing).
In addition we replaced our aging Vagrant development VM with an internal project called Minibox, based on Minikube. It includes tooling that helps developers move their work into production (by autogenerating Helm charts, etc.) and fulfills our vision of a fully Kubernetes and Helm-based software development pipeline, all the way from local to production.
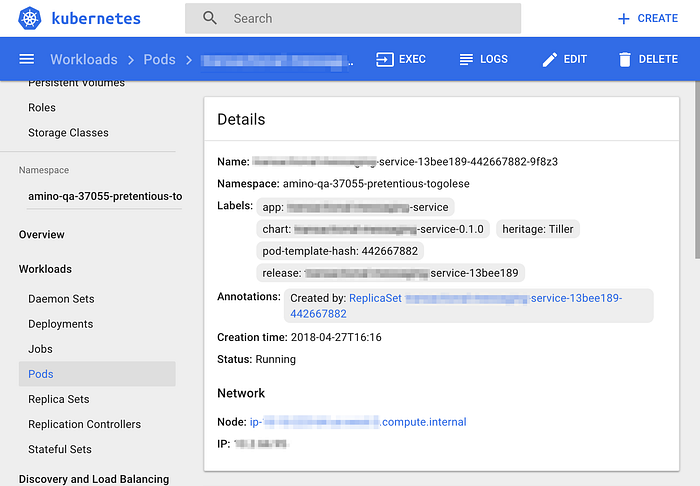
When we onboard new engineers to the team, Minibox, Acyl and the DQA workflow are some of the first things that they are introduced to. All engineers have direct kubectl access to their environments for debugging and we have documentation explaining how to use it. Teammates who have moved on have told us that one of the things they miss the most about working in DSC Engineering is the DQA system.
Does it sound fun to work on systems like this? DSC is hiring!
